7 Schnittstellen
Für den lesenden Zugriff auf PICA-Daten gibt es unAPI für einzelne Datensätze und SRU zur Abfrage von Suchergebnissen. Darüber hinaus können PICA-Daten manuell über die OPAC-Oberfläche und mit WinIBW heruntergeladen werden. Über die Avram-API können Informationen zu Anwendungsprofilen abgerufen werden.
7.1 unAPI
Die unAPI-Schnittstelle ermöglicht den Abruf einzelner PICA-Datensätze mittels ihrer PPN. Zusätzlich muss ein Datenbankkürzel angegeben werden und in welchem Format der Datensatz zurückgeliefert werden soll.
Eine Liste aller unterstützen Formaten wird bei Aufruf der unAPI-URL (https://unapi.k10plus.de/) zurückgeliefert. Die PICA-basierten Serialisierungen sind:
format= |
Serialisierung |
|---|---|
pp |
PICA Plain |
picajson |
PICA/JSON |
picaxml |
PICA/XML |
normpp |
Normalisiertes PICA |
extpp |
Binäres PICA |
Alle weiteren Formate (marcxml, mods36…) werden durch Konvertierung aus PICA erzeugt.
Beispiel auf der Kommandozeile
Der Datensatz mit der PPN 161165839X aus dem K10plus-Verbundkatalog (opac-de-627) lässt sich im PICA Plain Format (pp) unter der URL http://unapi.k10plus.de/.qmd#opac-de-627:ppn:161165839X&format=pp abrufen. Auf der Unix-Kommandozeile ist dies beispielsweise mit curl möglich so dass und anschließend mit picadata (Kapitel 8) weiterverarbeitet werden:
curl 'http://unapi.k10plus.de/.qmd#opac-de-627:ppn:161165839X&format=pp' | picadata '028A|028C'028A $9079339735$VTpv1$7gnd/118540475$3161149200$wpiz$AGoldman$DEmma$E1869$M1940
028C $9549565094$VTpv3$7gnd/133610519$3299969355$wpiz$APetersen$DTina$E1973$BBearb.
028C $9634784293$VTpv4$7gnd/142220213$3329568302$wpiz$ABreitinger$DMarlen$BÜbers.Für wiederkehrende Abrufe mit unterschiedlicher PPN lohnt es sich ein Shell-Skript anzulegen, das dann beispielsweise als ./kxp 161165839X aufgerufen werden kann:
cat <<EOF > kxp
#!/bin/bash
kxp() { curl -s "http://unapi.k10plus.de/?format=pp&id=opac-de-627:ppn:$1"; echo; echo; }
if [ -z "$1" ]; then while read -r ppn; do kxp "$ppn"; done
else for ppn in "$@"; do kxp "$ppn"; done; fi
EOF
chmod +x kxpBeispiel im Browser
Die Darstellung an dieser Stelle wird gerade überarbeitet!
In die folgende CodeMirror-Instanz können PICA-Datenätze per unAPI aus dem K10plus-Katalog geladen werden:
Die Web-Komponente PicaEditor unterstützt ebenfalls den Zugriff auf Katalogdaten per unAPI.
7.2 SRU
Die SRU-Schnittstelle dient der Abfrage von Datensätzen aus PICA-Katalogen mittels Suchanfragen. Die Suche erfolgt wie bei der klassischen OPAC-Oberfläche über einen Suchindex mit Suchschlüsseln. Jeder Suchschlüssel hat eine interne Nummer (“IKT”) und ein Kürzel aus drei Buchstaben. So ist beispielsweise die ISBN in IKT 7 mit dem Suchschlüssel ISB indexiert. Für OPAC-Suchanfragen in diesem Index gibt es jeweils entsprechende Suchanfragen an den SRU-Endpunkt des Katalogs:
- https://opac.k10plus.de/DB=2.299/CMD?ACT=SRCHA&IKT=7&TRM=9783894018108
- http://sru.k10plus.de/opac-de-627?version=1.1&operation=searchRetrieve&query=pica.isb=9783894018108&maximumRecords=10&recordSchema=picaxml
Eine Liste aller Suchschlüssel einer Datenbank ist über die Basis-URL des SRU-Endpunktes (z.B. http://sru.k10plus.de/opac-de-627) abrufbar und kann folgendermaßen in eine übersichtliche Form gebracht werden:
curl http://sru.k10plus.de/opac-de-627 | catmandu convert XML --path //index to XML | egrep -o '\[[^<]+'In den Katalogisierungsrichtlinien finden sich auch Angaben dazu, welche PICA-(Unter)felder in welchem Suchindex indexiert werden. Die Beziehung zwischen PICA-Feldern und Suchindex ist allerdings komplexer, da die Daten bei der Indexierung aggregiert, gefiltert und verändert werden können.
Beispiel: K10plus-Abfragen
Zum Testen einer SRU-Anfrage an die K10plus-Datenbank kann mit Catmandu (und der in Kapitel 9 angegebenen Konfiguration) ein einzelner Datensatz per PPN abgerufen werden:
catmandu convert kxp --query "pica.ppn=161165839X" to ppDer Titel ist in Feld 045H mit der Klasse 335.83092 (“Anarchisten”) der Dewey Dezimalklassifikation (DDC) erschlossen:
$ catmandu convert kxp --query "pica.ppn=161165839X" to pp | picadata 045H\$a
335.83092Die DDC ist im Suchindex mit dem Schlüssel ddc erfasst. Wie viele so erfassten Publikationen über Anarchisten gibt es im im K10plus? Hier mehrere Möglichkeiten der Auswertung. Die letzte Variante ruft nur die Anzahl der Datensätze ab:
catmandu convert kxp --query "pica.ddc=335.83092" to Count
catmandu convert kxp --query "pica.ddc=335.83092" to pp | picadata --count
catmandu convert kxp --query "pica.ddc=335.83092" --parser meta --limit 0 --fix 'retain(numberOfRecords)'Mehrere Suchschlüssel können mit and oder or verknüpft werden. Hier eine Liste der Titel von Publikationen zu Anarchisten die im Jahr 2014 oder 2015 erschienen sind:
catmandu convert kxp --query "pica.ddc=335.83092 and (pica.jah=2014 or pica.jah=2015)" to pp | picadata 021AFür komplexere Aufgaben empfiehlt es sich das Ergebnis der SRU-Anfrage nur einmal abzufragen und in eine Datei zu schreiben und anschließend mit verschiedenen Werkzeuge zu analysieren:
catmandu convert kxp --query pica.ddc=335.83092 to pp > ana.pica
picadata 021A ana.pica # Titelfelder
picadata '011@$a' ana.pica # Jahreszahlen
catmandu convert pp --fix 'pica_map(011@$a,jahr); remove_field(record)' to CSVDie Abfrage von Titeln die mit einem Normdatensatz verknüpft sind ist etwas komlizierter. Zunächst muss die PPN des Normdatensatzes ermittelt werden, beispielsweise auf Grundlage der GND-ID 2085624-6.
$ catmandu convert kxpnorm --query "pica.nid=2085624-6" to JSON | jq -r .[]._id
100221165Mit der PPN lässt sich anschließend eine CQL-Query wie pica.1049=100221165 and pica.1045=rel-tt and pica.1001=b bilden und zur Abfrage von Titeldatensätzen verwenden:
catmandu convert kxpnorm --query "pica.1049=100221165 and pica.1045=rel-tt and pica.1001=b" to pp | picadata -p '003@,021A'Beispiel: GND-Abfrage
Die PICA-Datenbank der Gemeinsamen Normdatei (GND) ist als Online-GND (OGND) per SRU abfragbar. Mit Kenntnis des GND-Format und der Suchschlüssel lassen sich gezielt GND-Datensätze im Internformat abrufen.
Der Suchschlüssel KSK enthält beispielsweise die vollständige Vorzungsbenennung eines Geografikums oder einer Organisation. Die Suche nach “Frankfurt am Main” liefert einen Treffer, die Suche nach “Frankfurt” keine Treffer:
catmandu convert ognd --query 'pica.ksk="Frankfurt am Main"' to Count
catmandu convert ognd --query 'pica.ksk=Frankfurt' to CountIm Suchschlüssel KOR werden Suchbegriffe auch als einzelne Worte erfasst. Zu Frankfurt gibt es mehr als 15.000 Treffer (mit dem Parameter --total lässt sich die Ergebnismenge bei Bedarf beschränken, um nur testweise die erste Datensätze abzurufen). Durch Eingrenzung des Normdatentyps auf Gebietskörperschaften und Verwaltungseinheiten (gik) lässt sich die Treffermenge auf etwa 350 verringern, die Abfrage dauert dennoch einige Sekunden:
catmandu convert ognd --query 'pica.kor=Frankfurt and pica.9001=gik' to pp > frankfurts.pica
picadata --count frankfurts.picaDie so heruntergeladene Treffermenge lässt sich nun mit der Catmandu-Konvertierungssprache “Fix” weiter bearbeiten. Hier ein Beispielskript:
# 003U: GND-Identifier
pica_map('003U$a', uri)
# 065@ : Geografikum, Variante Namen
pica_map('065@$axzg', alias.$append, join:', ')
# 065Q: Geografikum – Bevorzugter Name
pica_map('065A$a', name)
# entferne ursprünglichen PICA+ Datensatz
remove_field(record)
remove_field(_id)
Das Fix-Skript abgespeichert in der Datei gnd.fix, lässt sich folgendermaßen anwenden, um die Namen zu extrahieren:
catmandu convert pp --fix gnd.fix to YAML < frankfurts.pica7.3 OPAC
In der Standard-Katalogansicht eines PICA-Katalogs (OPAC) lässt sich der PICA-Datensatz eines ausgewählten Titels über einen versteckten Link direkt unter dem Icon der Publikationsform aufrufen (siehe Screenshot). Alternativ kann die lässt Feldansicht auch durch den URL-Bestandteil /PSR=PP (nur Titelebene) bzw. /PRS=PP%7F (alle Ebenen) aktiviert werden. Der Datensatz in PICA Plain Serialisierung kann anschließend per Copy & Paste beispielsweise in eine Datei kopiert werden.
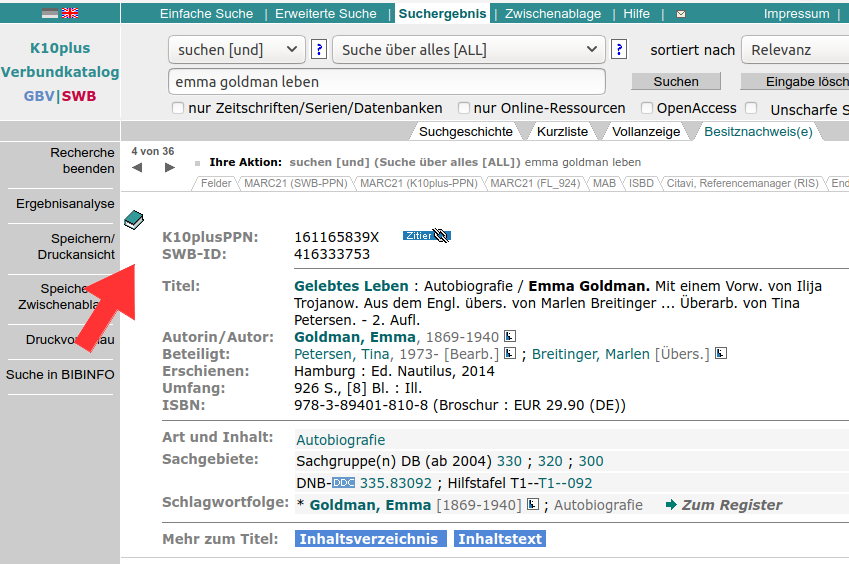
Unter dem PICA-Datensatz wird in der Feldansicht auch die Indexierung des Datensatz angezeigt (siehe Erklärungen zu SRU).
7.4 WinIBW
WinIBW (siehe Kapitel 13) ist zwar nicht frei verfügbar aber das in Bibliotheken am weitesten verbreitete Programm zur Verarbeitung von PICA-Daten. Nicht zuletzt werden PICA-Daten bei der Katalogisierung in der Regel mittels WinIBW in PICA-Datenbanken eingetragen.
7.5 Avram-API
Neben den oben genannten Möglichkeiten zum Zugriff auf PICA-Daten gibt es mit der Avram-API eine Schnittstelle zum Zugriff auf Schema-Informationen (Avram Schemas). Abrufbar sind Informationen zu PICA-Feldern und Unterfeldern ausgehend von Feldnummern in PICA+ und Pica3 (Abfrage-Parameter field bzw. pica3) oder alle Felder eines Anwendungsprofils (Abfrage-Parameter profile).
Die Avram-API für den K10Plus-Katalog steht unter https://format.k10plus.de/avram.pl zur Verfügung und ist dort dokumentiert. So lässt sich beispielsweise mit der URL https://format.k10plus.de/avram.pl?pica3=4000&profile=k10plus abrufen, wie das Pica3-Feld 4000 im K10Plus-Format definiert ist:
Ein Beispiel für die Verwendung der Schnittstelle liefert die Web-Komponente PicaEditor.